Java基础面试题:集合
1. 介绍Java中的Collection FrameWork
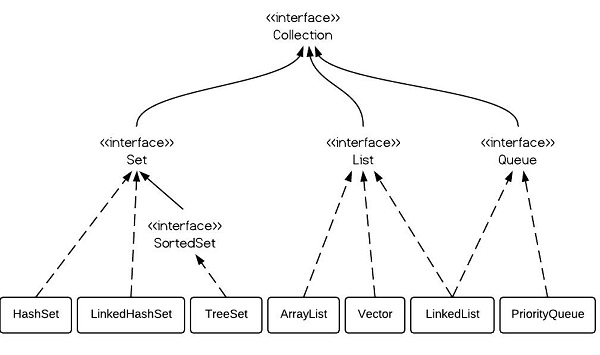
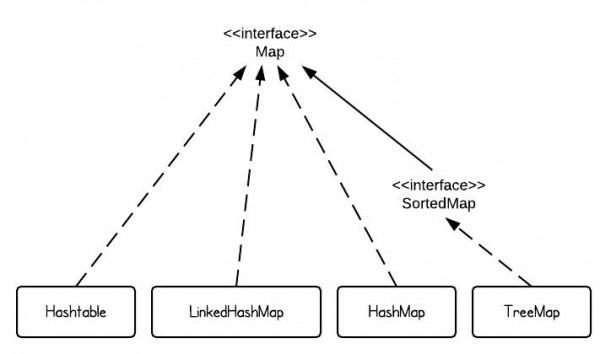
2. 说说常见的集合有哪些
Map 接口和 Collection 接口是所有集合框架的父接口:
- Collection 接口的子接口包括:Set 接口和 List 接口;
- Map 接口的实现类主要有:HashMap、TreeMap、Hashtable、ConcurrentHashMap 以及 Properties 等;
- Set 接口的实现类主要有:HashSet、TreeSet、LinkedHashSet 等;
- List 接口的实现类主要有:ArrayList、LinkedList、Stack 以及 Vector 等。
3. HashMap 和 Hashtable 的区别有哪些
HashMap 没有考虑同步,是线程不安全的;Hashtable 使用了 synchronized 关键字,是线程安全的;
前者允许 null 作为 Key;后者不允许 null 作为 Key。
4. HashMap 的底层实现你知道吗
在 Java8 之前,其底层实现是数组 + 链表实现,Java8 使用了数组 + 链表 + 红黑树实现。此时你可以简单的在纸上画图分析。
5. ConcurrentHashMap 和 Hashtable 的区别
ConcurrentHashMap 结合了 HashMap 和 HashTable 二者的优势。
HashMap 没有考虑同步,hashtable 考虑了同步的问题。但是 hashtable 在每次同步执行时都要锁住整个结构。
ConcurrentHashMap 锁的方式是稍微细粒度的。 ConcurrentHashMap 将 hash 表分为 16 个桶(默认值),诸如 get,put,remove 等常用操作只锁当前需要用到的桶。
6. ConcurrentHashMap 的具体实现知道吗
该类包含两个静态内部类 HashEntry 和 Segment;前者用来封装映射表的键值对,后者用来充当锁的角色;
Segment 是一种可重入的锁 ReentrantLock,每个 Segment 守护一个 HashEntry 数组里得元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment 锁。
7. HashMap 的长度为什么是 2 的幂次方
通过将 Key 的 hash 值与 length-1 进行 & 运算,实现了当前 Key 的定位,2 的幂次方可以减少冲突(碰撞)的次数,提高 HashMap 查询效率;
如果 length 为 2 的次幂 则 length-1 转化为二进制必定是 11111……的形式,在于 h 的二进制与操作效率会非常的快,而且空间不浪费;
如果 length 不是 2 的次幂,比如 length 为 15,则 length-1 为 14,对应的二进制为 1110,在于 h 与操作,最后一位都为 0,而 0001,0011,0101,1001,1011,0111,1101 这几个位置永远都不能存放元素了,空间浪费相当大。
更糟的是这种情况中,数组可以使用的位置比数组长度小了很多,这意味着进一步增加了碰撞的几率,减慢了查询的效率!这样就会造成空间的浪费。
8. List 和 Set 的区别是啥
List 元素是有序的,可以重复;Set 元素是无序的,不可以重复。
9. List、Set 和 Map 的初始容量和加载因子
List
ArrayList 的初始容量是 10;加载因子为 0.5; 扩容增量:原容量的 0.5 倍 +1;一次扩容后长度为 16。
Vector 初始容量为 10,加载因子是 1。扩容增量:原容量的 1 倍,如 Vector 的容量为 10,一次扩容后是容量为 20。
Set
HashSet,初始容量为 16,加载因子为 0.75; 扩容增量:原容量的 1 倍; 如 HashSet 的容量为 16,一次扩容后容量为 32
Map
HashMap,初始容量 16,加载因子为 0.75; 扩容增量:原容量的 1 倍; 如 HashMap 的容量为 16,一次扩容后容量为 32
10. Comparable 接口和 Comparator 接口有什么区别
前者简单,但是如果需要重新定义比较类型时,需要修改源代码。
后者不需要修改源代码,自定义一个比较器,实现自定义的比较方法。
11. Java 集合的快速失败机制 "fail-fast"
它是 java 集合的一种错误检测机制,当多个线程对集合进行结构上的改变的操作时,有可能会产生 fail-fast 机制。
例如 :
假设存在两个线程(线程 1、线程 2),线程 1 通过 Iterator 在遍历集合 A 中的元素,在某个时候线程 2 修改了集合 A 的结构(是结构上面的修改,而不是简单的修改集合元素的内容),那么这个时候程序就会抛出 ConcurrentModificationException 异常,从而产生 fail-fast 机制。
原因:
迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个 modCount 变量。集合在被遍历期间如果内容发生变化,就会改变 modCount 的值。
每当迭代器使用 hashNext()/next() 遍历下一个元素之前,都会检测 modCount 变量是否为 expectedmodCount 值,是的话就返回遍历;否则抛出异常,终止遍历。
解决办法:
在遍历过程中,所有涉及到改变 modCount 值得地方全部加上 synchronized;
使用 CopyOnWriteArrayList 来替换 ArrayList。
12. List、Set、Map是否继承自Collection接口
List,Set 是;Map 不是。
13. 你所知道的集合类都有哪些
最常用的集合类是List 和Map。
List 的具体实现包括ArrayList 和Vector,它们是可变大小的列表,比较适合构建、存储和操作任何类型对象的元素列表。List 适用于按数值索引访问元素的情形。
Map 提供了一个更通用的元素存储方法。Map 集合类用于存储元素对(称作“键”和“值”),其中每个键映射到一个值。
14. ArrayList,Vector,LinkedList的存储性能和特性
ArrayList 和Vector 都是使用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,它们都允许直接按序号索引元素,但是插入元素要涉及数组元素移动等内存操作,所以索引数据快而插入数据慢,Vector 由于使用了synchronized 方法(线程安全),通常性能上较ArrayList 差,而LinkedList 使用双向链表实现存储,按序号索引数据需要进行前向或后向遍历,但是插入数据时只需要记录本项的前后项即可,所以插入速度较快。
15. Collection和Collections的区别
Collection 是java.util 下的接口,它是各种集合的父接口,继承于它的接口主要有Set 和List。
Collections 是个java.util 下的类,是针对集合的帮助类,提供一系列静态方法实现对各种集合的搜索、排序、线程安全化等操作。
16. HashMap和Hashtable的区别
二者都实现了Map 接口,是将惟一键映射到特定的值上。
主要区别在于:
- HashMap 没有排序,允许一个null 键和多个null 值,而Hashtable 不允许;
- HashMap 把Hashtable 的contains 方法去掉了,改成containsvalue 和containsKey,因为contains 方法容易让人引起误解;
- Hashtable 继承自Dictionary 类,HashMap 是Java1.2 引进的Map 接口的实现;
- Hashtable 的方法是Synchronize 的,而HashMap 不是,在多个线程访问Hashtable 时,不需要自己为它的方法实现同步,而HashMap 就必须为之提供外同步。Hashtable 和HashMap 采用的hash/rehash 算法大致一样,所以性能不会有很大的差异。
17. Arraylist与Vector区别
就ArrayList 与Vector 主要从二方面来说:
- 同步性:Vector 是线程安全的(同步),而ArrayList 是线程序不安全的。
- 数据增长:当需要增长时,Vector 默认增长一倍,而ArrayList 却是一半。
18. List,Map,Set存取元素时各有什么特点
List 以特定次序来持有元素,可有重复元素。
Set 无法拥有重复元素,内部排序。
Map 保存key-value 值,value 可多值。
19. Set里元素用什么方法来区分重复
Set 里的元素是不能重复的,用equals()方法来区分重复与否。覆盖equals()方法用来判断对象的内容是否相同,而”==”判断地址是否相等,用来决定引用值是否指向同一对象。